BARBI Workflow
Pratheepa Jeganathan
Department of Statistics, Stanford Universityjpratheepa31@gmail.com
BARBI.RmdAbstract
BAyesian Reference analysis with Background Interference (BARBI) provides a reliable statistical method to remove contaminating bacterial DNA from both high- and low-biomass samples.Install R and RStudio. Open this Rmd rmarkdown file in vignettes folder in RStudio. Then run the following code to install all required packages, including BARBI from Github repository.
pkgs <- c("phyloseq",
"dplyr",
"HDInterval",
"grid",
"gtable",
"gridExtra",
"magrittr",
"ggplot2",
"DESeq2")
if (!requireNamespace("BiocManager")){
install.packages("BiocManager")
}
BiocManager::install(setdiff(pkgs, installed.packages()))
devtools::install_github("PratheepaJ/BARBI")## devtools (2.2.1 -> 2.2.2 ) [CRAN]
## dplyr (0.8.3 -> 0.8.4 ) [CRAN]
## rstan (2.19.2 -> 2.19.3 ) [CRAN]
## tidyr (1.0.0 -> 1.0.2 ) [CRAN]
## BH (1.72.0-2 -> 1.72.0-3) [CRAN]
## StanHeaders (2.19.0 -> 2.19.2 ) [CRAN]
## callr (3.4.0 -> 3.4.2 ) [CRAN]
## cli (2.0.0 -> 2.0.1 ) [CRAN]
## digest (0.6.23 -> 0.6.24 ) [CRAN]
## DT (0.11 -> 0.12 ) [CRAN]
## jsonlite (1.6 -> 1.6.1 ) [CRAN]
## remotes (2.1.0 -> 2.1.1 ) [CRAN]
## rstudioapi (0.10 -> 0.11 ) [CRAN]
## foreach (1.4.7 -> 1.4.8 ) [CRAN]
## tidyselect (0.2.5 -> 1.0.0 ) [CRAN]
## R.methodsS3 (1.7.1 -> 1.8.0 ) [CRAN]
## loo (2.1.0 -> 2.2.0 ) [CRAN]
## stringi (1.4.3 -> 1.4.6 ) [CRAN]
## vctrs (0.2.1 -> 0.2.3 ) [CRAN]
## gh (1.0.1 -> 1.1.0 ) [CRAN]
## yaml (2.2.0 -> 2.2.1 ) [CRAN]
## fansi (0.4.0 -> 0.4.1 ) [CRAN]
## mime (0.8 -> 0.9 ) [CRAN]
## processx (3.4.1 -> 3.4.2 ) [CRAN]
## ps (1.3.0 -> 1.3.2 ) [CRAN]
## farver (2.0.1 -> 2.0.3 ) [CRAN]
## prettyunits (1.0.2 -> 1.1.1 ) [CRAN]
## checkmate (1.9.4 -> 2.0.0 ) [CRAN]
##
## The downloaded binary packages are in
## /var/folders/70/2611_qjd0sdbxlcny0wp4xx40000gn/T//Rtmp6mYrNY/downloaded_packages
##
checking for file ‘/private/var/folders/70/2611_qjd0sdbxlcny0wp4xx40000gn/T/Rtmp6mYrNY/remotes1e341bb13d2b/PratheepaJ-BARBI-09af5c5/DESCRIPTION’ ...
✓ checking for file ‘/private/var/folders/70/2611_qjd0sdbxlcny0wp4xx40000gn/T/Rtmp6mYrNY/remotes1e341bb13d2b/PratheepaJ-BARBI-09af5c5/DESCRIPTION’
##
─ preparing ‘BARBI’:
##
checking DESCRIPTION meta-information ...
✓ checking DESCRIPTION meta-information
##
─ cleaning src
##
─ checking for LF line-endings in source and make files and shell scripts
##
─ checking for empty or unneeded directories
##
─ looking to see if a ‘data/datalist’ file should be added
##
─ building ‘BARBI_0.1.0.tar.gz’
##
## Load packages:
library(BARBI)
library(phyloseq)
library(dplyr)
library(HDInterval)
library(grid)
library(gtable)
library(gridExtra)
library(magrittr)
library(ggplot2)
library(DESeq2)
library(reshape2)
library(ggwordcloud)Example dataset
We load an example dataset stored as a phyloseq object in the BARBI package (or use your own data stored as a phyloseq object)
Load the phyloseq object
We validated our the BARBI method for removing DNA contamination using a dilution series of samples of eight known bacterial species in the standard ZymoBIOMICS microbial community (Zymo Research).
We saved this data as phyloseq object in the BARBI package.
Seven rounds of six-fold dilutions from the standard, from 1:1 up to 1:279,936 (\(n_{1} = 8\)), as well as ten negative extraction controls \(n_{2} = 10\), were made.
Then all \(N =18\) specimens were processed and analyzed with the ZymoBIOMICS® Service: Targeted Metagenomic Sequencing (Zymo Research, Irvine, CA), which leverages 16S rRNA gene sequencing.
Specify that the samples are on the columns and taxa are on the rows of otu_table.
Adding blocks/batches
To reduce the batch-effects of contamination, we can specify the block information and analyze each block separately with BARBI.
We highly recommend that you keep track of batch effects (Especially DNA extraction and library prep batches), visualize your data with PCA on ranks, and separate your data into different blocks of necessary.
In the example dataset, all samples are in one block.
Remove taxa not in dilution series samples
Identify the taxa that are not present in at least one dilution series sample and removed them from the phyloseq object. Label these species as contaminants.
ps <- prune_taxa(taxa_sums(ps) > 0, ps)
ps_specimen <- subset_samples(ps,
SampleType %in% c("Standard"))
prevTaxaP <- apply(otu_table(ps_specimen), 1,
function(x){sum(x>0)})
Contaminants1 <- names(prevTaxaP)[prevTaxaP == 0]
ps <- prune_taxa(prevTaxaP > 0, ps)
ps## phyloseq-class experiment-level object
## otu_table() OTU Table: [ 53 taxa and 18 samples ]
## sample_data() Sample Data: [ 18 samples by 5 sample variables ]
## tax_table() Taxonomy Table: [ 53 taxa by 7 taxonomic ranks ]We identified 142 ASVs not is any dilution series samples, and they are classified as contaminants before using BARBI.
We use BARBI to infer true ASVs in each dilution series sample.
Library depth
We check the distribution of sample library depth to see whether there are samples with very small library depth that should be dropped from the analysis.
totalReads <- colSums(otu_table(ps))
hist(log(totalReads),
yaxs="i",
xaxs="i",
main="Distribution of total reads per sample",
breaks=50)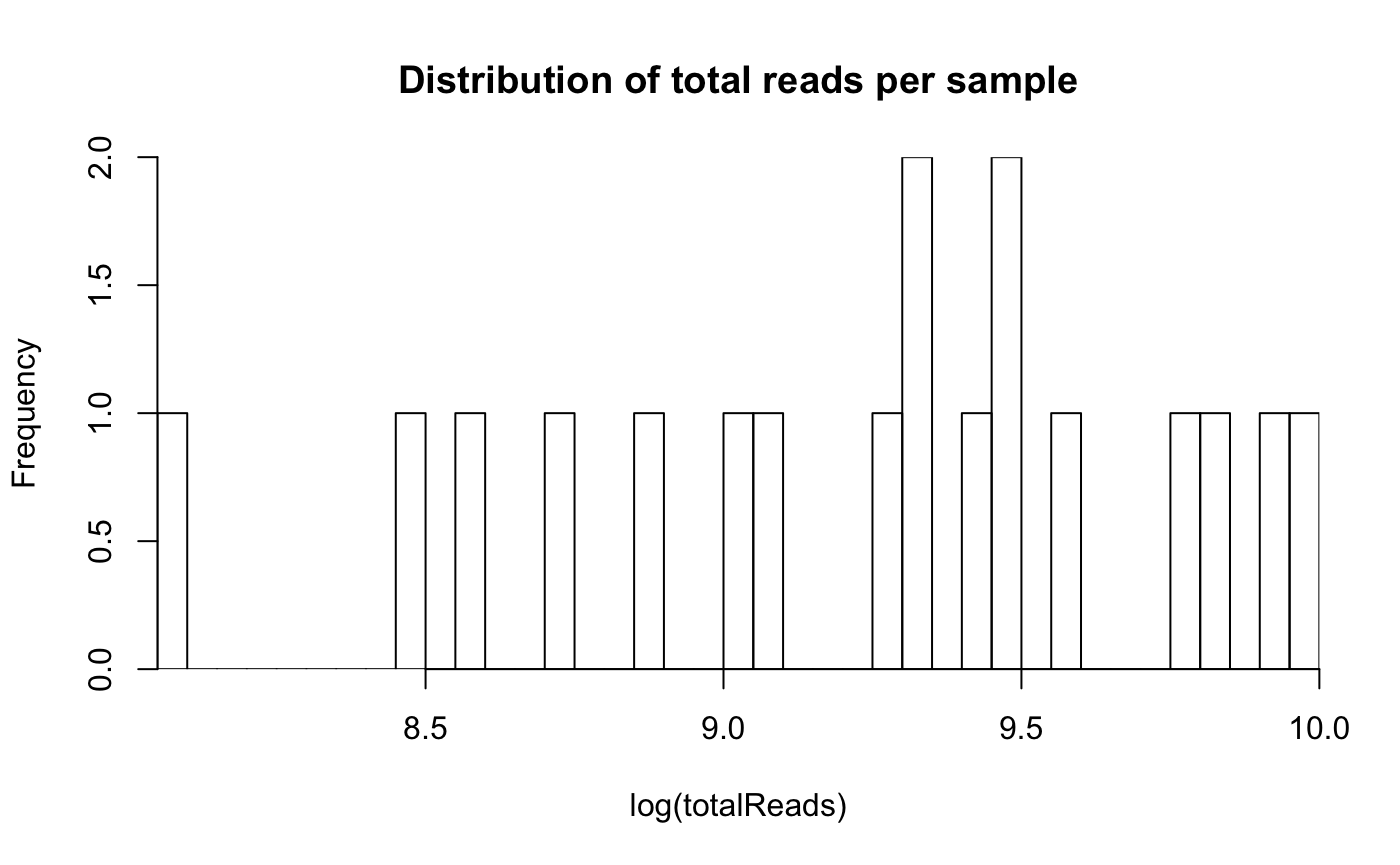
We do not need to drop any sample.
BARBI
Prepare the phyloseq object for the BARBI method
We use BARBI to identify contaminants in each block separately. Thus, we split the phyloseq object into multiple phyloseq objects corresponding to each block, and store the phyloseq objects as a list of phyloseq objects, psByBlock.
We select negative control samples from each block and store as a list of phyloseq objects, psNCbyBlock.
We select all taxa that have a prevalence of zero (i.e., have zero reads) in all negative control samples for each block and store as a list of phyloseq objects, psallzeroInNC.
We select all specimen samples from each block and store as a list of phyloseq objects, psPlByBlock.
psBlockResult <- psBlockResults(ps,
sampleTypeVar = "SampleType",
caselevels = c("Standard"),
controllevel = c("Negative"),
sampleName = "sampleID",
blockVar = "block")
psByBlock <- psBlockResult[[1]]
psNCbyBlock <- psBlockResult[[2]]
psallzeroInNC <- psBlockResult[[3]]
psPlByBlock <- psBlockResult[[4]]Estimate the density parameters for the contaminant intensities in negative control samples
Estimate the gamma density parameters for the contaminant intensities using the negative control samples for each block.
\(\lambda_{il}^{(c)} \sim \text{gamma }\left(\frac{1}{\gamma_{i}^{0}},\frac{1}{\gamma_{i}^{0} \mu_{il}^{0}}\right),\) \(l\) is the \(l\)-th negative control.
Estimate the density parameters for the contaminant intensities in each specimen
For each specimen, we estimate the gamma density parameters for the contaminant intensities using the scaling property of the gamma distribution.
\(\lambda_{ij}^{(c)} \sim \text{gamma }\left( \frac{d^{0}_{l} }{d_{j}} \frac{1}{\gamma_{i}^{0}},\frac{1}{\gamma_{i}^{0} \mu_{il}^{0}}\right),\) where \(j\) is the \(j\)-th specimen.
num_blks <- length(con_int_neg_ctrl)
blks <- seq(1, num_blks) %>% as.list
con_int_specimen <- lapply(blks, function(x){
con_int_specimen_each_blk <- alphaBetaContInPlasma(psPlByBlock = psPlByBlock,
psallzeroInNC = psallzeroInNC,
blk = x,
alphaBetaNegControl = con_int_neg_ctrl)
return(con_int_specimen_each_blk)
})Sample from the marginal posterior for the true intensities
For all specimen samples and for all taxa, sample from the posterior for the true intensities using the Metropolis-Hasting MCMC.
We need to specify the number of iterations in the MCMC using the option itera.
Save the gamma prior for the intensity of contamination and the posterior samples.
The suggested itera is 10,000.
itera = 100
t1 <- proc.time()
mar_post_true_intensities <- lapply(blks,function(x){
mar_post_true_intensities_each_blk <- samplingPosterior(psPlByBlock = psPlByBlock,
blk = x,
gammaPrior_Cont = con_int_specimen[[x]],
itera = itera)
return(mar_post_true_intensities_each_blk)
})
proc.time()-t1## user system elapsed
## 7.266 0.102 7.413Make summaries from the BARBI results.
Make tables for each sample
Choose the number of MCMC to be removed using the option burnIn. It must be less than itera.
Choose the coverage probability to construct the highest posterior density (HPD) interval\(\left(L_{ij}^{(r)}, U_{ij}^{(r)}\right)\) (for each taxon \(i\) in a specimen \(j\)) using the option cov.pro for true intensities.
Compute the highest density interval (HDI) for the contaminant intensities \(\left(L_{ij}^{(c)}, U_{ij}^{(c)}\right)\) for each taxon \(i\) in a specimen \(j\).
For a contaminant taxon, the lower limit \(L_{ij}^{(r)}\) will be smaller than the upper limit \(U_{ij}^{(c)}\).
The suggested burnIn is 5000 for itera <- 10,000.
ASV <- as.character(paste0("ASV_",seq(1,ntaxa(ps))))
ASV.Genus <- paste0("ASV_",seq(1,ntaxa(ps)),"_",as.character(tax_table(ps)[,6]))
ASV.Genus.Species <- paste0(ASV,"_",as.character(tax_table(ps)[,6]),"_", as.character(tax_table(ps)[,7]))
df.ASV <- data.frame(seq.variant = taxa_names(ps), ASV = ASV, ASV.Genus = ASV.Genus, ASV.Genus.Species = ASV.Genus.Species)itera <- 100
burnIn <- 10
cov.pro <- .95
mak_tab <- FALSE # Save tables or print tables
# con_int_specimen_mar_post_true_intensities <- readRDS("./con_int_specimen_mar_post_true_intensities_vignettes.rds")
con_int_specimen <- con_int_specimen_mar_post_true_intensities[[1]]
mar_post_true_intensities <- con_int_specimen_mar_post_true_intensities[[2]]
## Keep true
all_true_taxa_blk <- list()
for(blk in 1:num_blks){
mar_post_true_intensities_blk <- mar_post_true_intensities[[blk]]
con_int_specimen_blk <- con_int_specimen[[blk]]
all_true_taxa <- character()
for(sam in 1:nsamples(psPlByBlock[[blk]])){
taxa_post <- mar_post_true_intensities_blk[[sam]]
acceptance <- list()
lower.r <- list()
upper.r <- list()
lower.c <- list()
upper.c <- list()
all.zero.nc <- list()
for(taxa in 1:length(taxa_post)){
burnIn <- burnIn
acceptance[[taxa]] <- 1 - mean(duplicated(taxa_post[[taxa]][-(1:burnIn),]))
HPD.r <- hdi(taxa_post[[taxa]][-(1:burnIn),],
credMass = cov.pro)
lower.r[[taxa]] <- round(HPD.r[1], digits = 0)
upper.r[[taxa]] <- round(HPD.r[2], digits = 0)
lamda.c <- rgamma((itera-burnIn+1),
shape= con_int_specimen_blk[[sam]][[1]][taxa],
rate = con_int_specimen_blk[[sam]][[2]][taxa])
HDI.c <- hdi(lamda.c, credMass = cov.pro)
lower.c[[taxa]] <- round(HDI.c[1], digits = 0)
upper.c[[taxa]] <- round(HDI.c[2], digits = 0)
all.zero.nc[[taxa]] <- con_int_specimen_blk[[sam]][[5]][taxa]
}
tax_names <- taxa_names(psPlByBlock[[blk]])
tax_names <- df.ASV$ASV.Genus[which(as.character(df.ASV$seq.variant) %in% tax_names)]
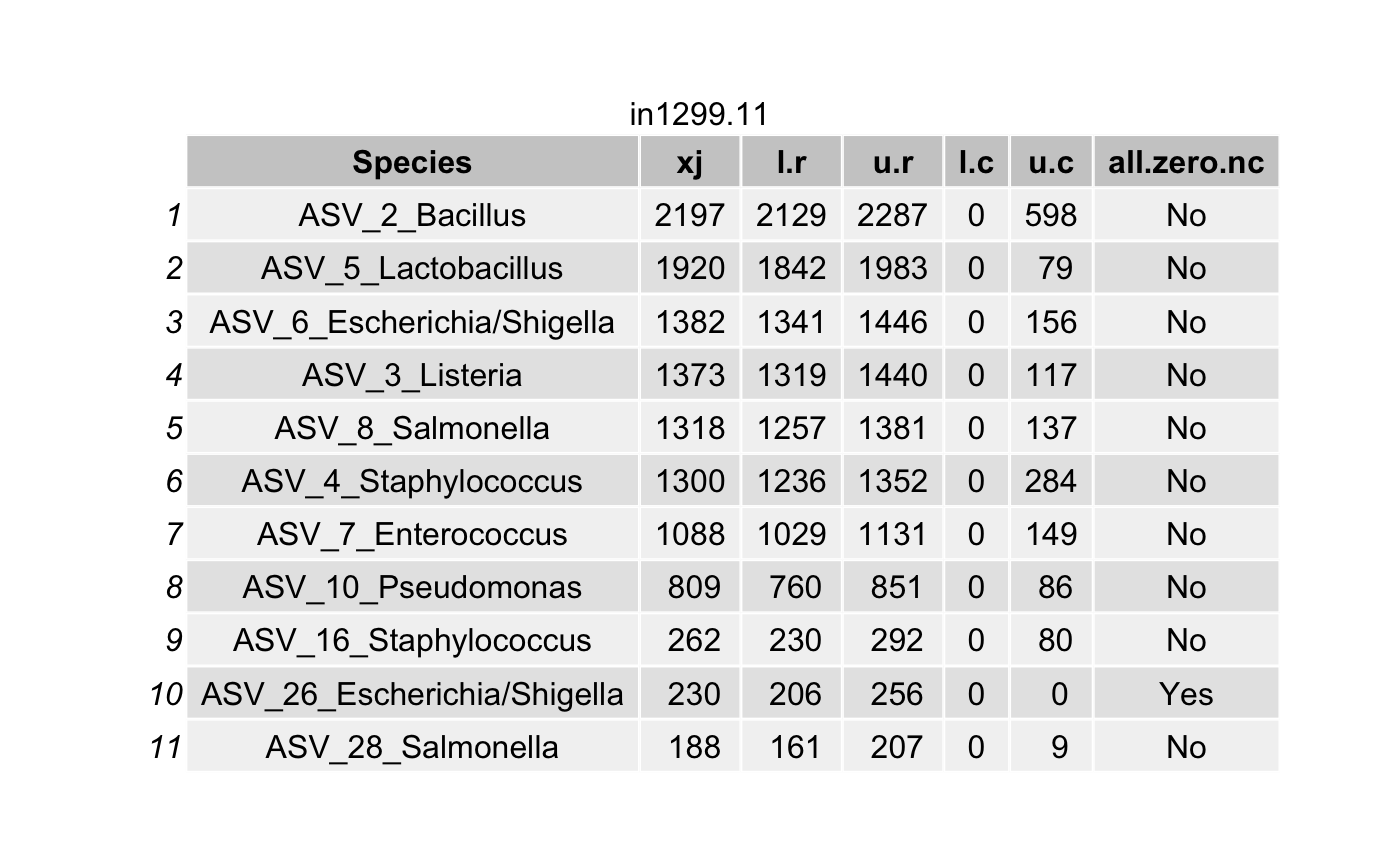
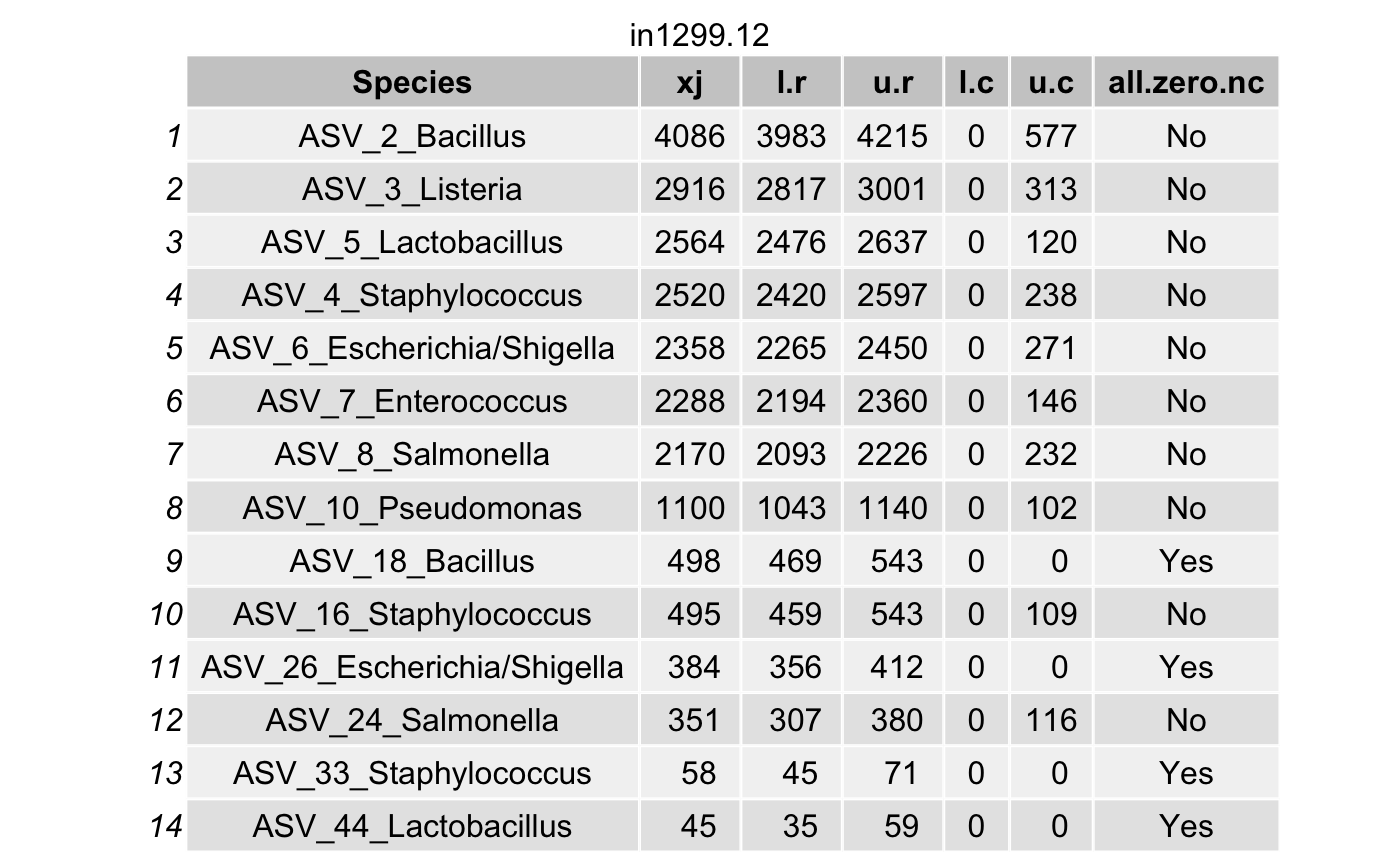
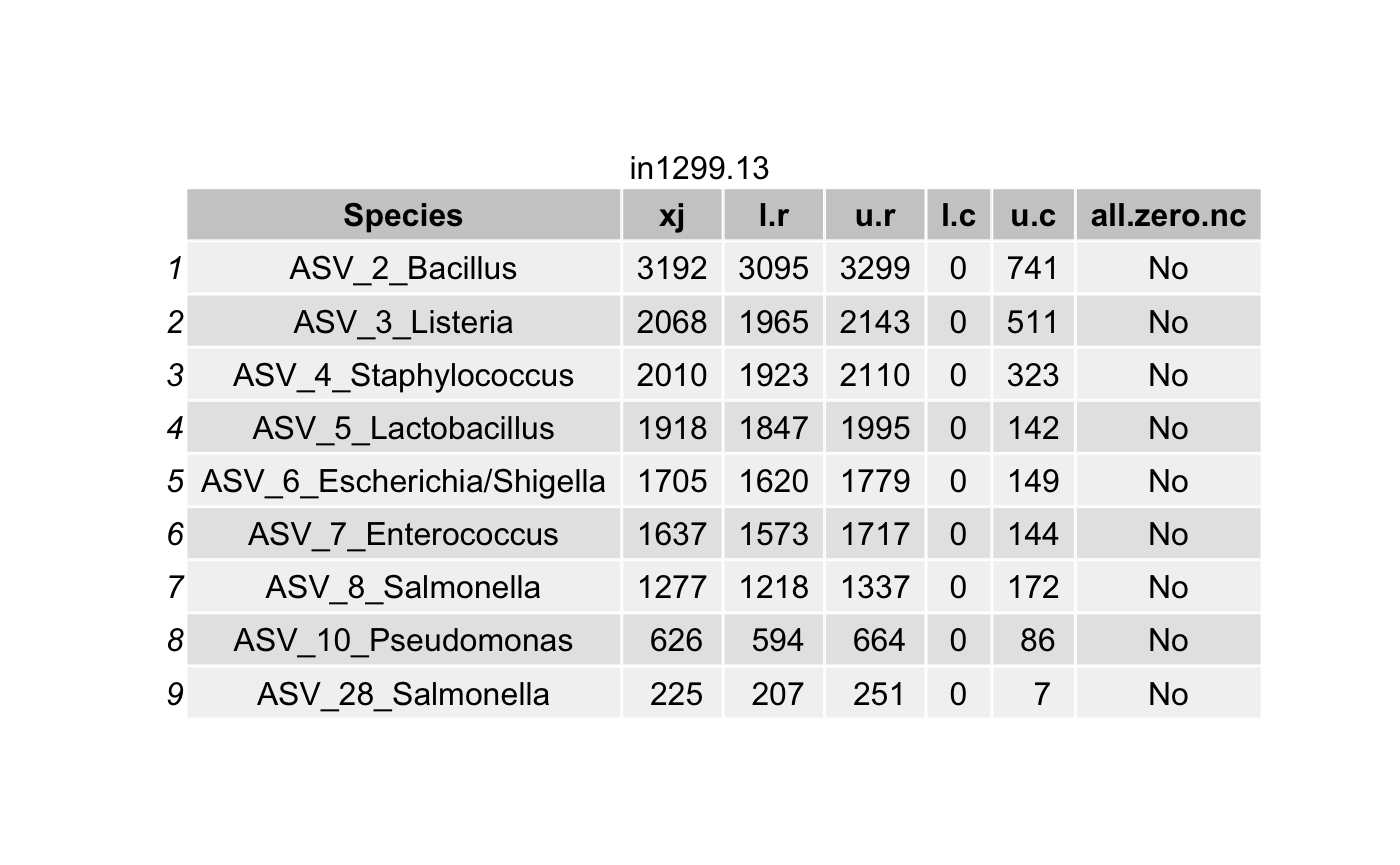
df <- data.frame(Species = tax_names,
xj = as.numeric(con_int_specimen_blk[[sam]][[3]]),
l.r = unlist(lower.r),
u.r = unlist(upper.r),
l.c = unlist(lower.c),
u.c = unlist(upper.c),
all.zero.nc = unlist(all.zero.nc))
# List all true taxa
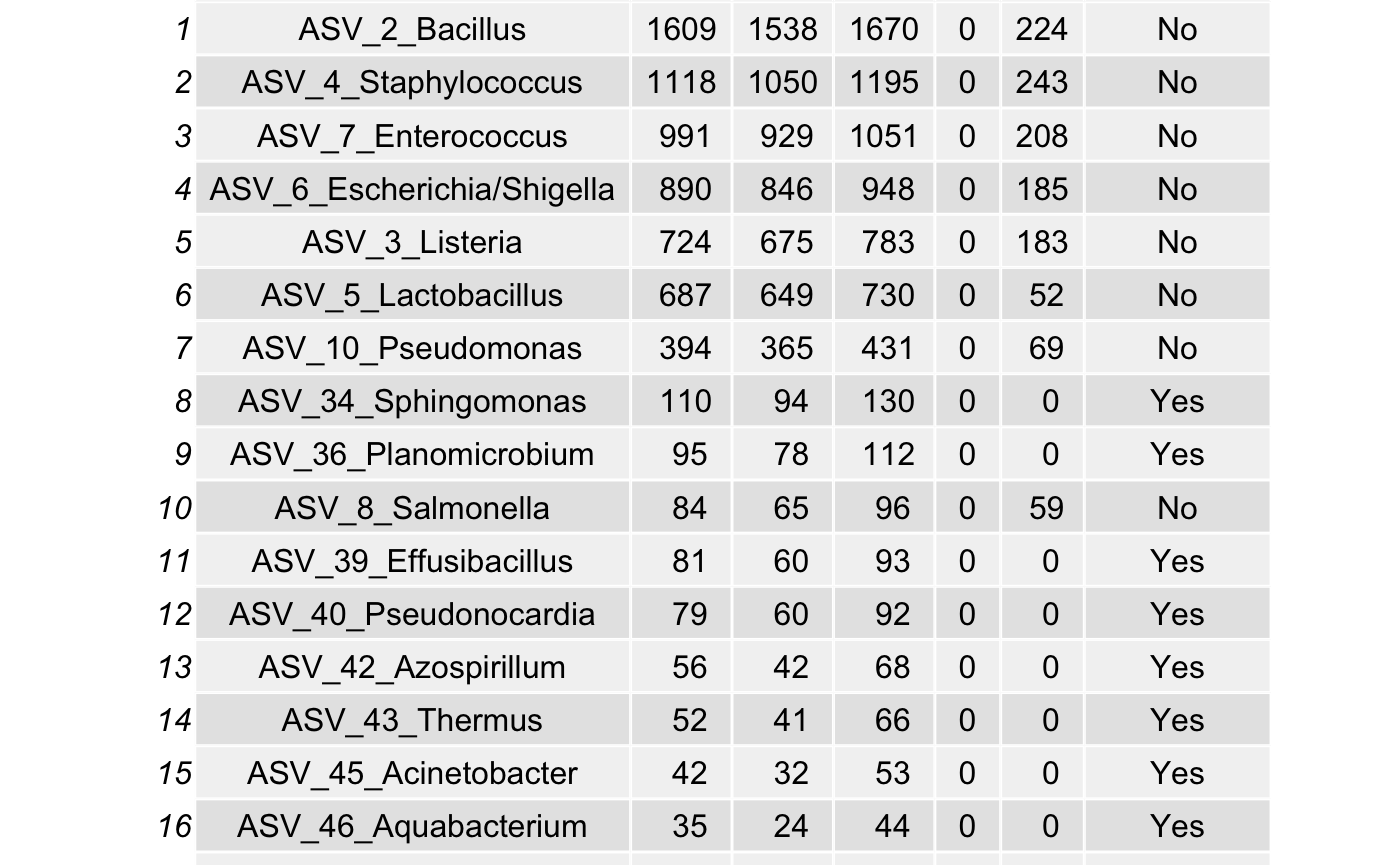
df <- arrange(filter(df,(l.r > u.c) & (l.r > 0)),
desc(xj))
# If there is no true taxa
if(dim(df)[1]==0){
df <- data.frame(Species="Negative",
xj="Negative",
l.r="Negative",
u.r="Negative",
l.c ="Negative",
u.c="Negative",
all.zero.nc = "Negative")
}
# collect all true taxa in the specimen
all_true_taxa <- c(all_true_taxa,
as.character(df$Species))
if(mak_tab){
filname <- paste("./",
sample_names(psPlByBlock[[blk]])[sam],
".png",
sep = "")
png(filname, height = 600, width = 750)
df.p <- tableGrob(df)
title <- textGrob(sample_names(psPlByBlock[[blk]])[sam],
gp = gpar(fontsize = 12))
padding <- unit(0.5,"line")
df.p <- gtable_add_rows(df.p,
heights = grobHeight(title) + padding,
pos = 0)
df.p <- gtable_add_grob(df.p,
list(title),
t = 1,
l = 1,
r = ncol(df.p))
grid.newpage()
grid.draw(df.p)
dev.off()
}else{
df.p <- tableGrob(df)
title <- textGrob(sample_names(psPlByBlock[[blk]])[sam],
gp = gpar(fontsize = 12))
padding <- unit(0.5,"line")
df.p <- gtable_add_rows(df.p,
heights = grobHeight(title) + padding,
pos = 0)
df.p <- gtable_add_grob(df.p,
list(title),
t = 1,
l = 1,
r = ncol(df.p))
grid.newpage()
grid.draw(df.p)
}
all_true_taxa <- unique(all_true_taxa)
}
all_true_taxa_blk[[blk]] <- all_true_taxa
}
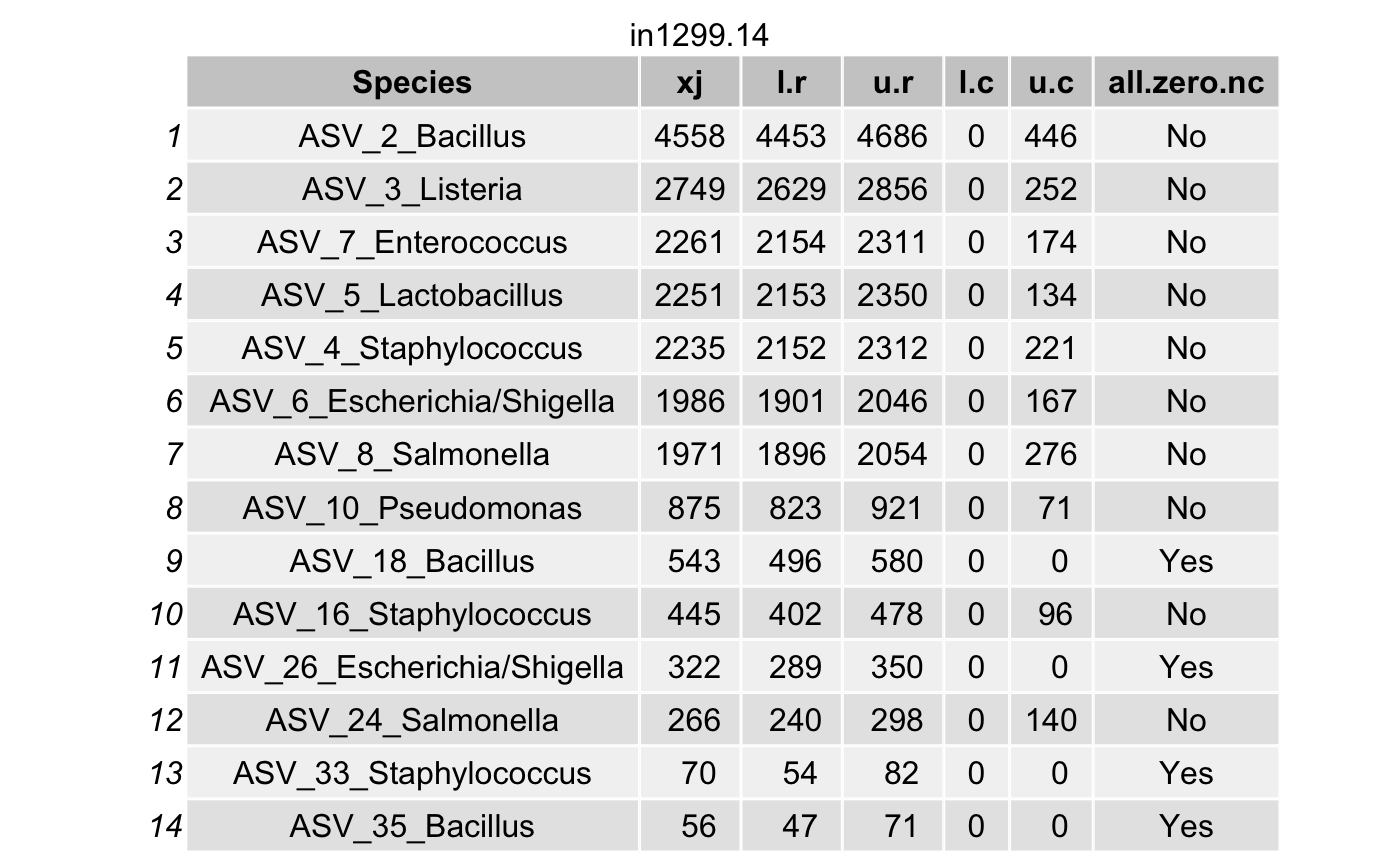
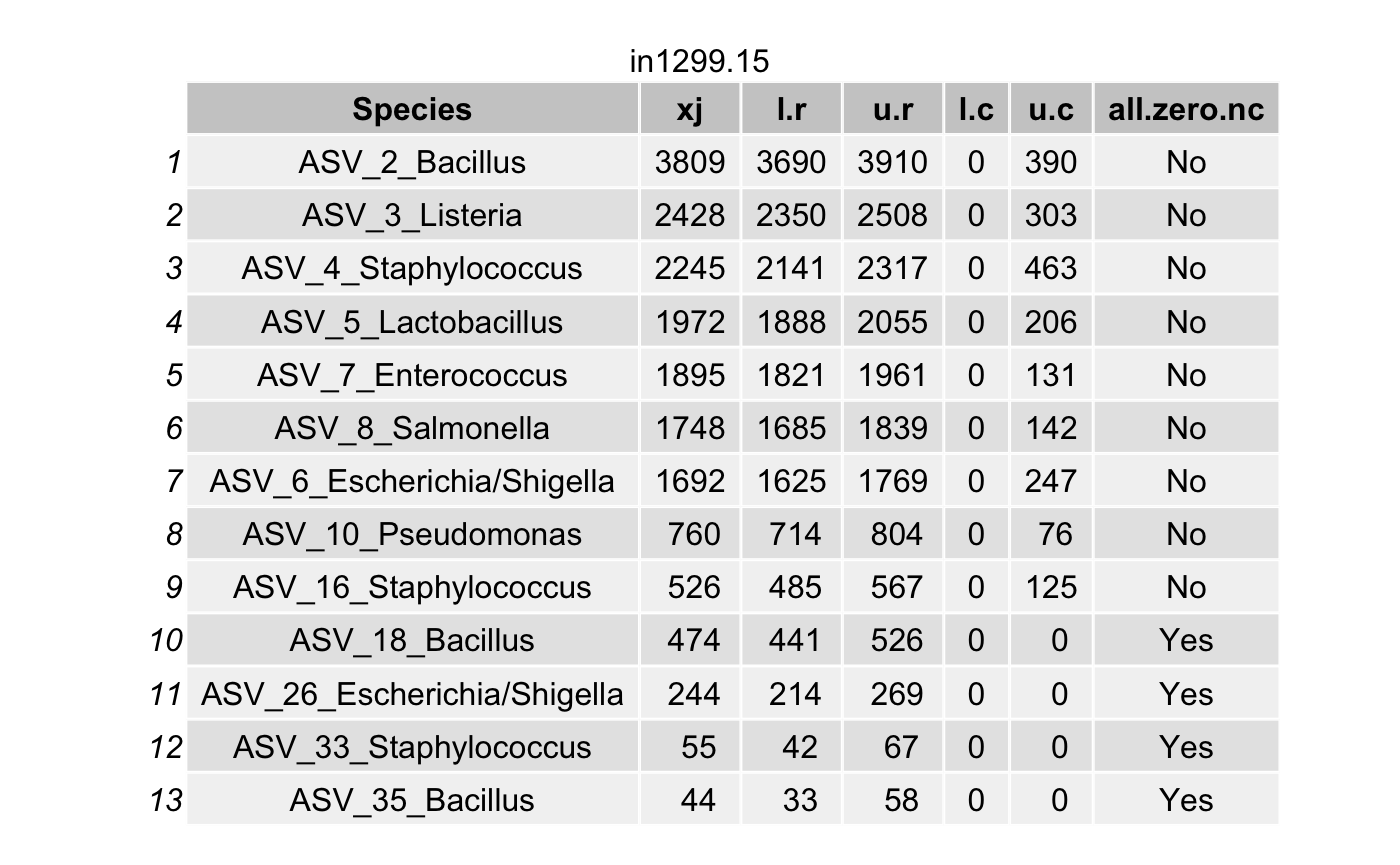
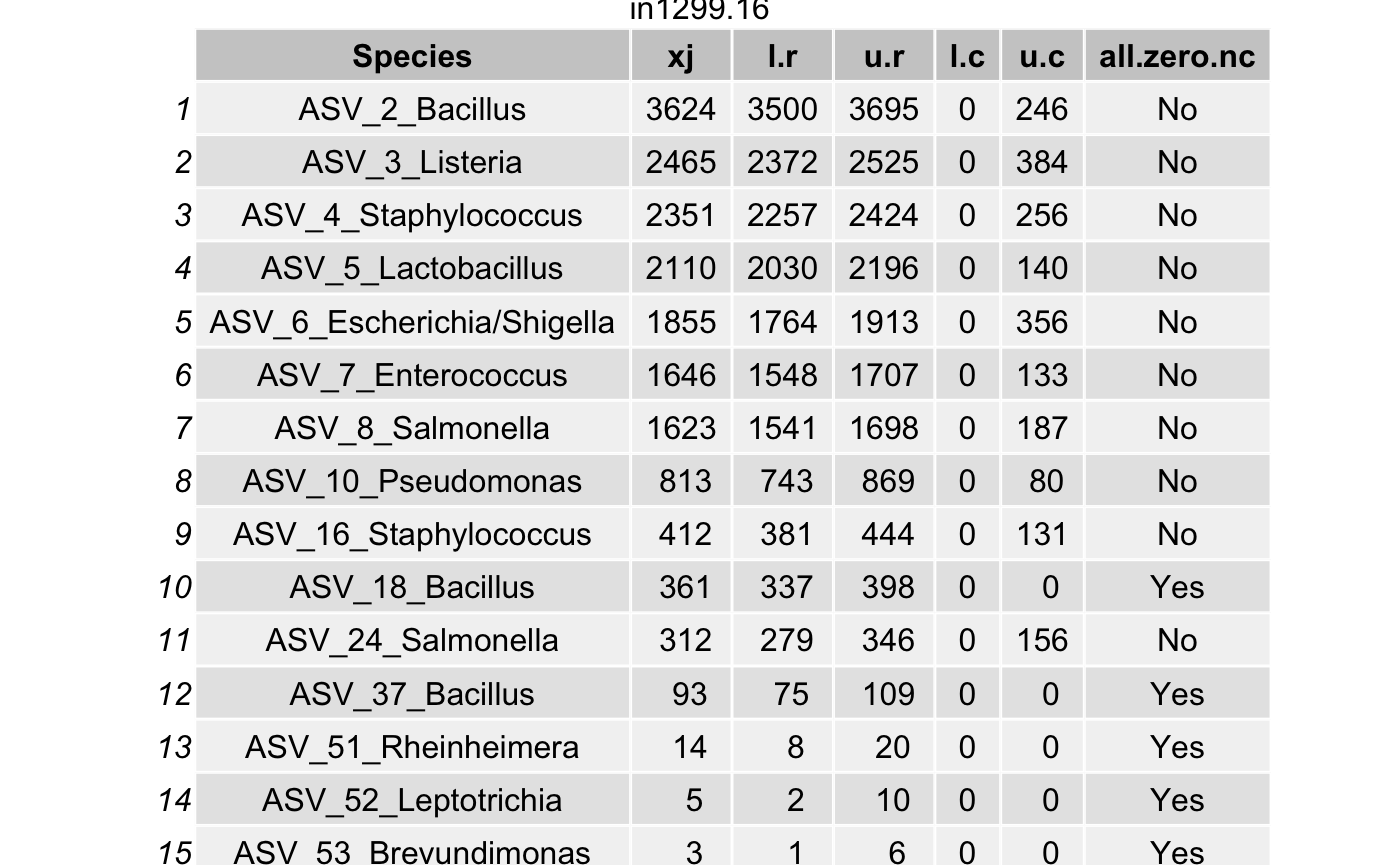
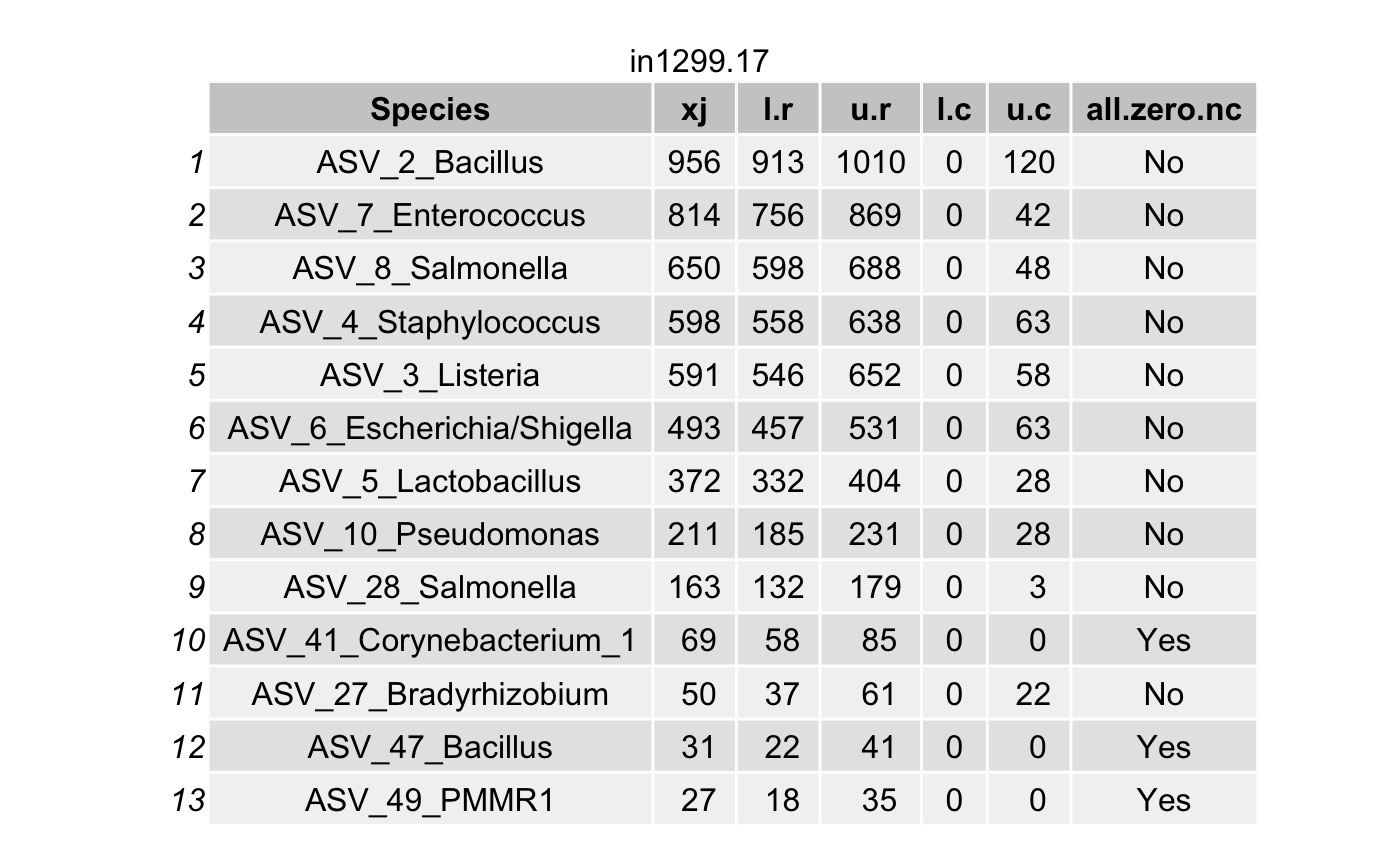
Construct a phyloseq object with the true taxa
all_true_taxa_blk <- unlist(all_true_taxa_blk)
ASV = df.ASV$seq.variant[which(as.character(df.ASV$ASV.Genus) %in% as.character(all_true_taxa_blk))] %>% as.character()
ps_decon <- prune_taxa(ASV, ps)
ps_decon## phyloseq-class experiment-level object
## otu_table() OTU Table: [ 34 taxa and 18 samples ]
## sample_data() Sample Data: [ 18 samples by 5 sample variables ]
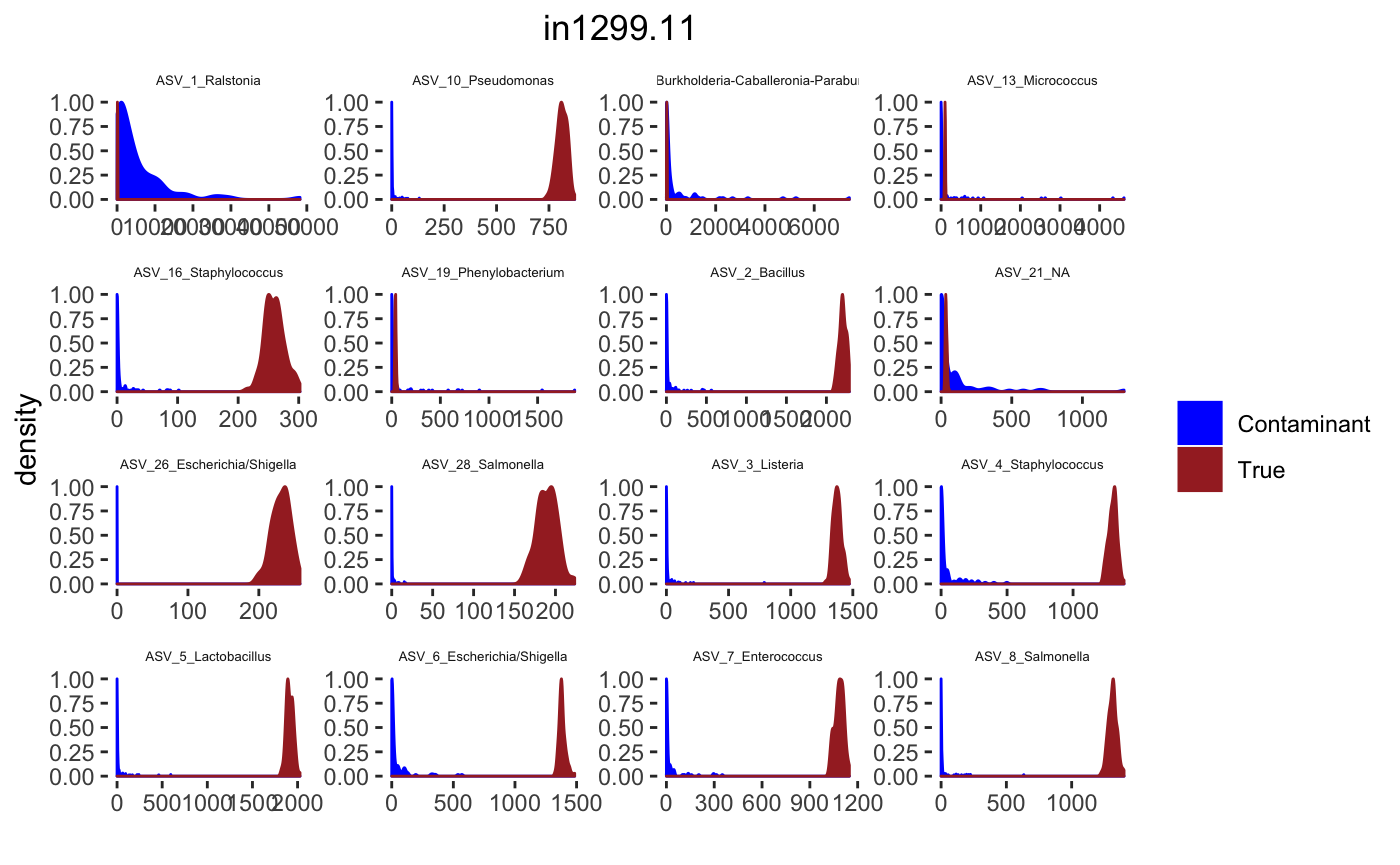
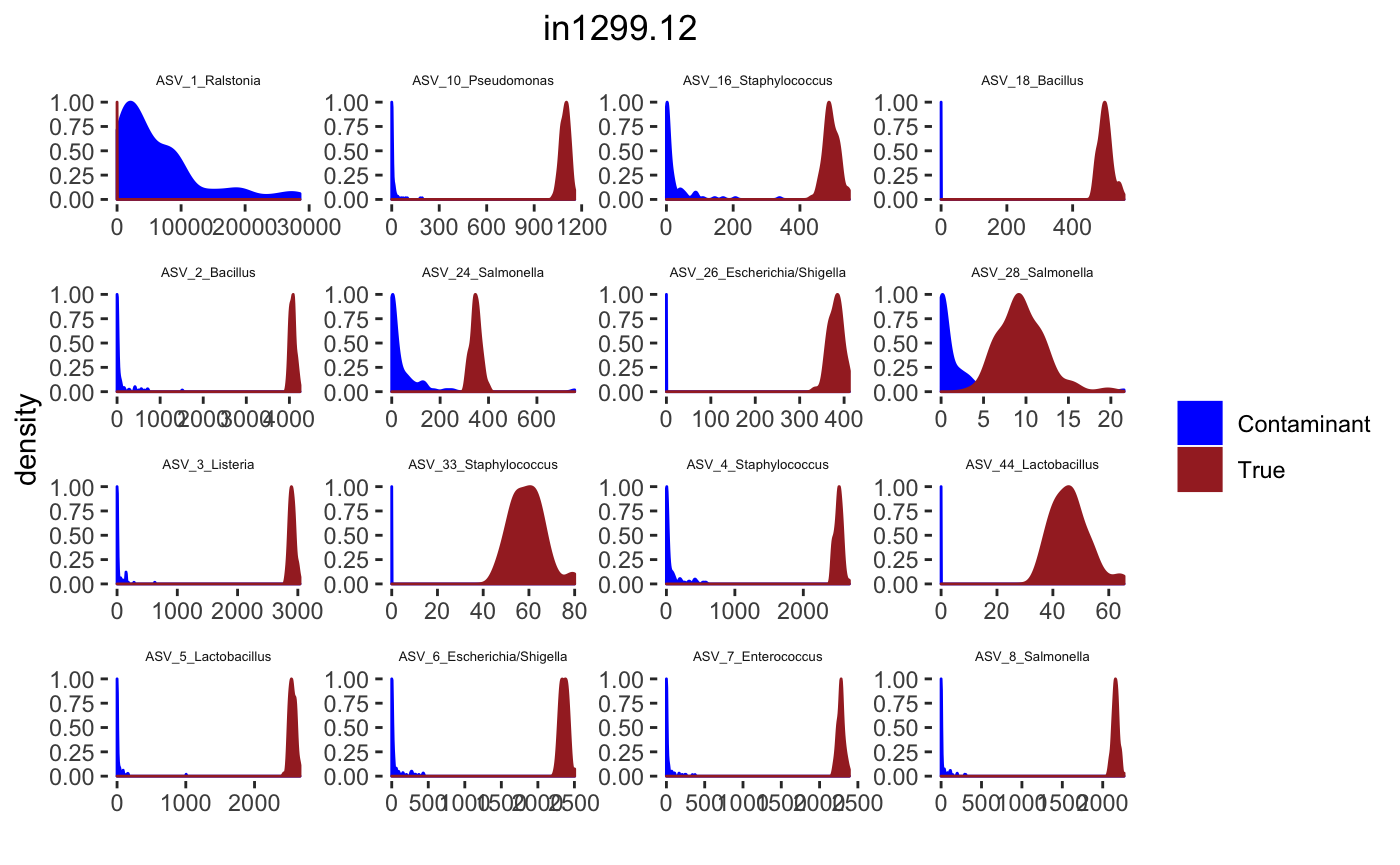
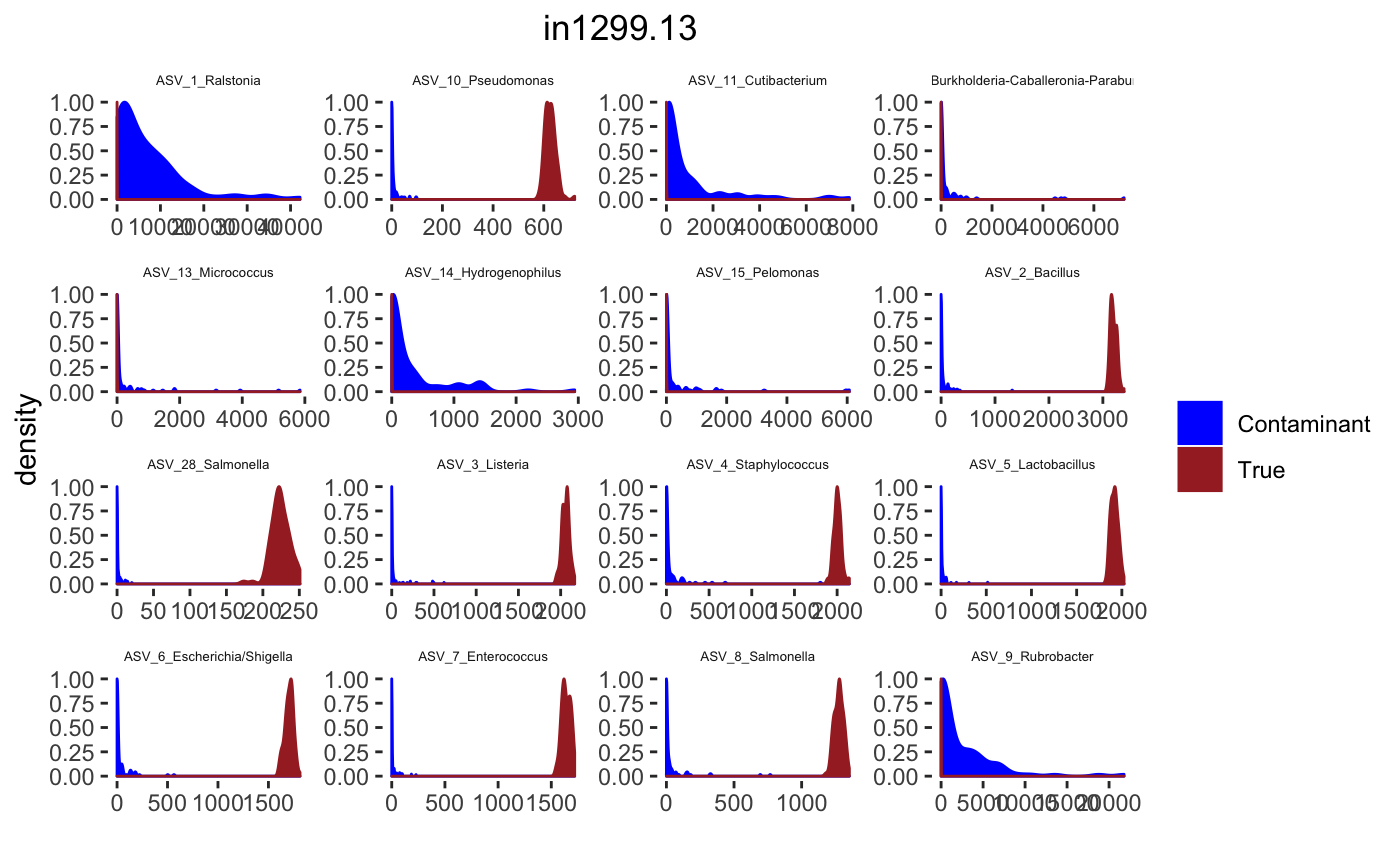
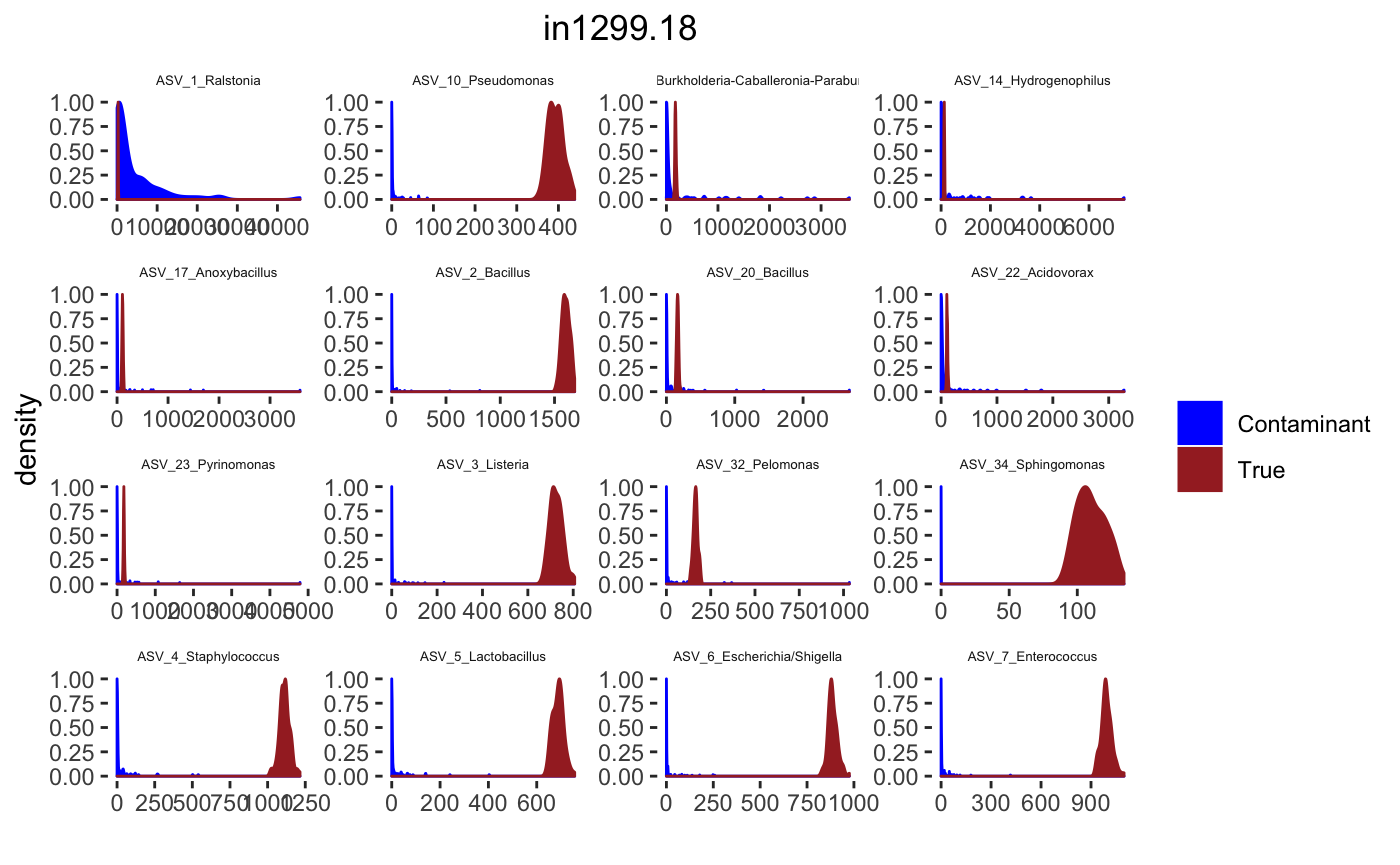
## tax_table() Taxonomy Table: [ 34 taxa by 7 taxonomic ranks ]Histograms
set.seed(10000)
itera <- 100
burnIn <- 10
cov.pro <- .95
num_blks <- length(psByBlock)
# con_int_specimen_mar_post_true_intensities <- readRDS("./con_int_specimen_mar_post_true_intensities_vignettes.rds")
con_int_specimen <- con_int_specimen_mar_post_true_intensities[[1]]
mar_post_true_intensities <- con_int_specimen_mar_post_true_intensities[[2]]
blk <- 1
con_int_specimen_blk <- con_int_specimen[[blk]]
mar_post_true_intensities_blk <- mar_post_true_intensities[[blk]]
sample.names <- sample_names(psPlByBlock[[blk]])
for(j in 1: length(sample.names)){
desired.sample.name <- sample.names[j]
desired.sample.index <- which(sample_names(psPlByBlock[[blk]]) %in% desired.sample.name)
tax_interested <- rownames(sort(otu_table(psPlByBlock[[blk]])[,desired.sample.index],decreasing = TRUE))[c(1:16)]
tax_interested_ind <- which(as.character(taxa_names(psPlByBlock[[blk]])) %in% tax_interested)
tax_names <- taxa_names(psPlByBlock[[blk]])[tax_interested_ind]
tax_names <- df.ASV$ASV.Genus[which(as.character(df.ASV$seq.variant) %in% tax_names)] %>% as.character()
taxa.post <- mar_post_true_intensities_blk[[desired.sample.index]]
burnIn <- burnIn
signal.hist <- taxa.post[tax_interested_ind]
signal.hist <- lapply(signal.hist,function(x){x[-(1:burnIn),]})
signal.df <- data.frame(do.call("cbind", signal.hist))
colnames(signal.df) <- tax_names
signal.df$group <- rep("True", length=dim(signal.df)[1])
bg <- list()
for(ind in 1:length(tax_interested_ind)){
bg[[ind]] <- rgamma((itera-burnIn+1),
shape = con_int_specimen_blk[[desired.sample.index]][[1]][tax_interested_ind[ind]],
rate = con_int_specimen_blk[[desired.sample.index]][[2]][tax_interested_ind[ind]])
}
bg.df <- data.frame(do.call("cbind",bg))
colnames(bg.df) <- tax_names
bg.df$group <- rep("Contaminant", length=dim(bg.df)[1])
bg.signal <- rbind(signal.df, bg.df)
bg.signal$group <- as.factor(bg.signal$group)
bg_sig_long <- tidyr::gather(bg.signal,key="Taxa",
value="Reads",1:(dim(bg.signal)[2]-1))
bg_sig_long$Taxa <- as.factor(bg_sig_long$Taxa)
p <- ggplot(bg_sig_long, aes(x= Reads))+
geom_density(aes(y = ..scaled.., fill = group, color = group)) +
facet_wrap(~Taxa,scales = "free")+
scale_fill_manual(values=c("blue","brown")) +
scale_color_manual(values=c("blue","brown")) +
ggtitle(desired.sample.name)+
theme(plot.title = element_text(hjust = 0.5),
legend.title=element_blank(),
strip.text.x = element_text(size=5),
strip.background = element_blank(),
panel.grid = element_blank(),
panel.background = element_blank()) +
xlab("") +
ylab("density")
print(p)
# fileN <- paste0("./Figures/", desired.sample.name,"_hist",".eps")
# ggsave(fileN, plot = p, width = 10, height = 5, device = "eps")
}
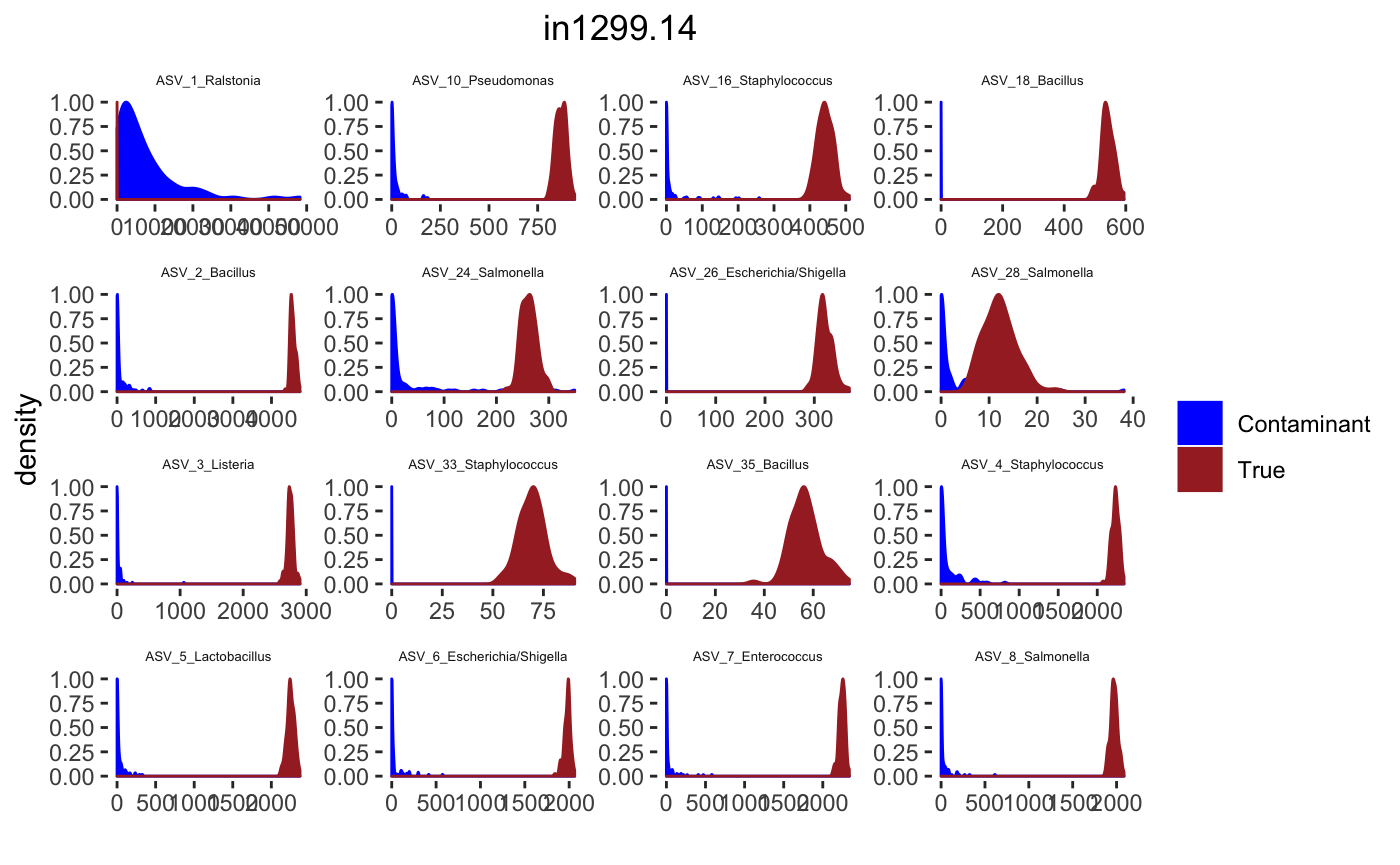
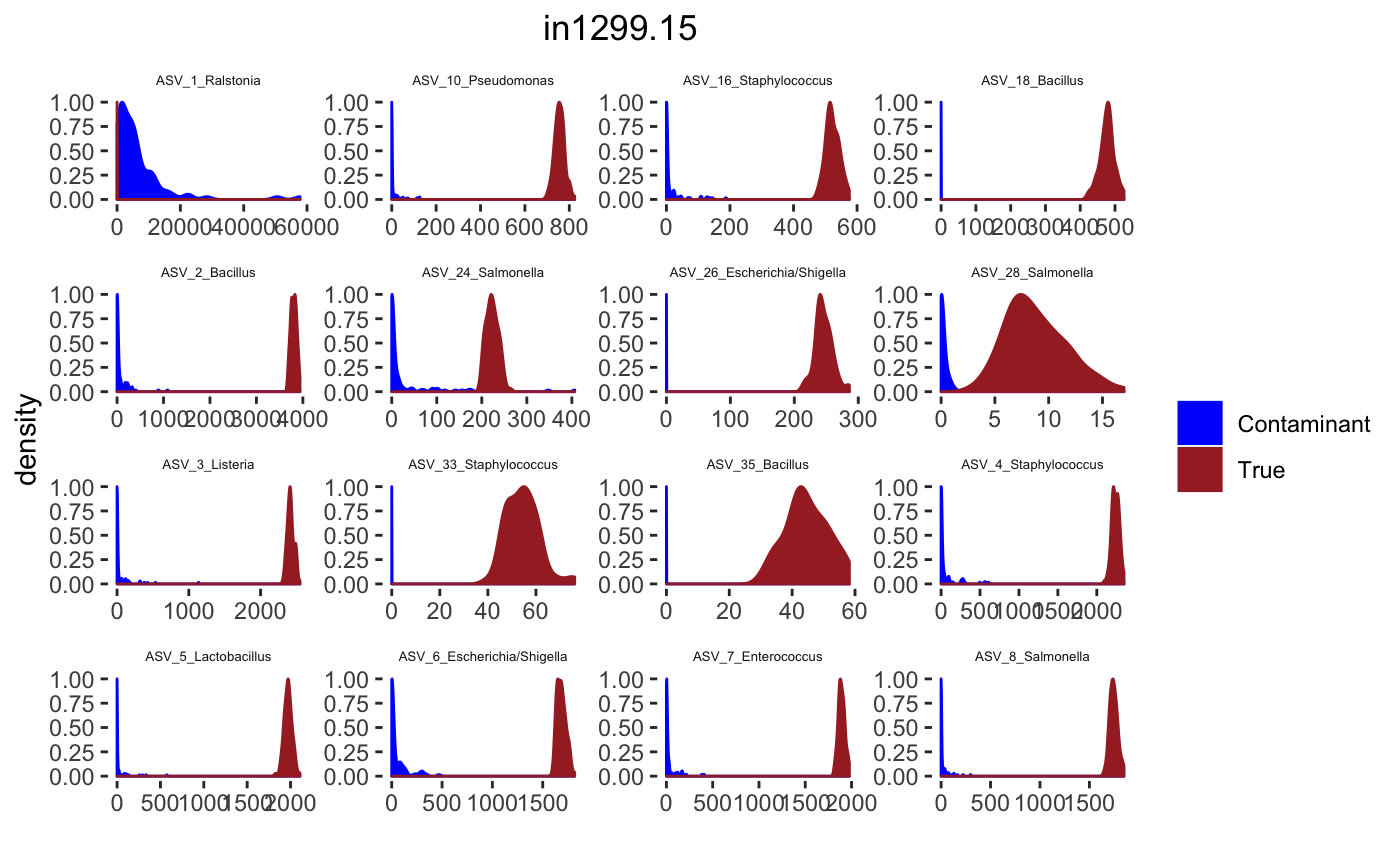
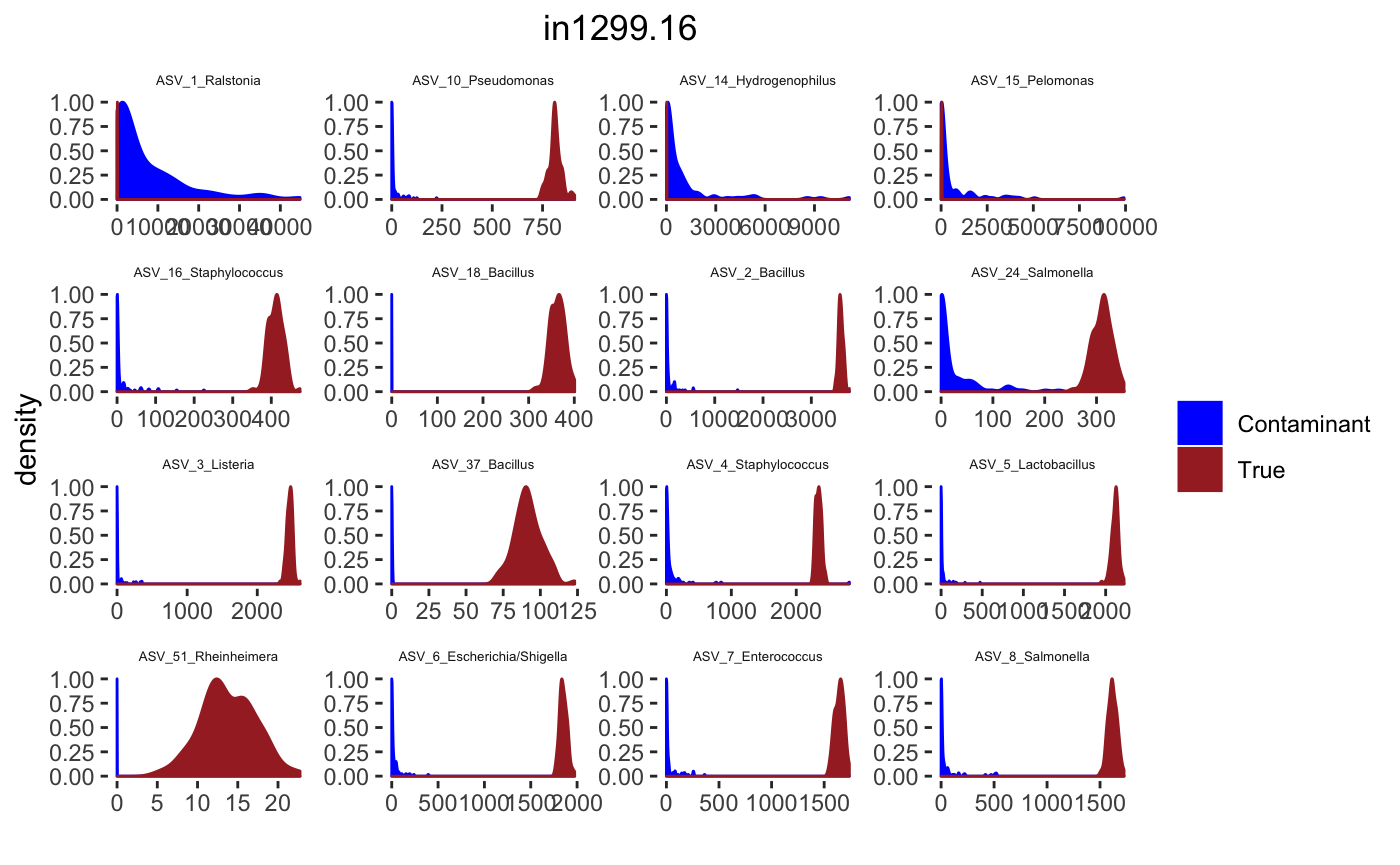
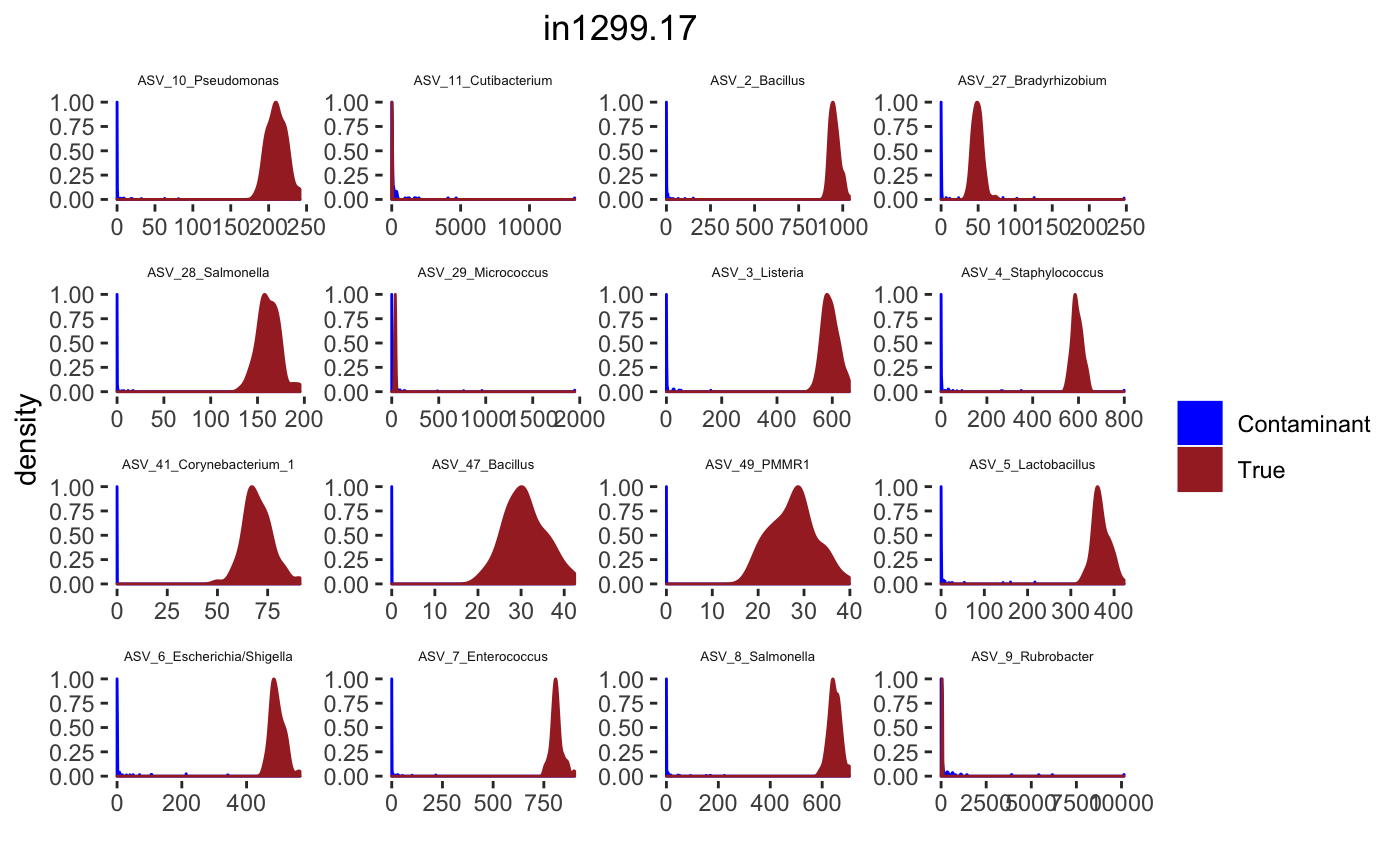
Latent Dirichlet Allocation
Co-occurrences of contaminants provide important information about their potential source and we provide a topic modeling approach that identifies “contaminant topics” and the distribution of taxa in each topic. This model helps identify contaminant sources related to each topic. This is important in the appropriate design of followup experiments.
short.sample.names = c(paste0("NC.", c(1,10)),
paste0("Di.", seq(1,8)),
paste0("NC.", seq(2,9)))
sample_names(ps) = short.sample.names
x = t(get_taxa(ps))
dimnames(x) = NULL
K = 4
stan.data <- list(K = K,
V = ncol(x),
D = nrow(x),
n = x,
alpha = rep(1, K),
gamma = rep(0.5, ncol(x))
)
stan.fit = LDAtopicmodel(stan_data = stan.data, iter = 100, chains = 1)##
## SAMPLING FOR MODEL 'lda' NOW (CHAIN 1).
## Chain 1:
## Chain 1: Gradient evaluation took 0.000393 seconds
## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 3.93 seconds.
## Chain 1: Adjust your expectations accordingly!
## Chain 1:
## Chain 1:
## Chain 1: WARNING: There aren't enough warmup iterations to fit the
## Chain 1: three stages of adaptation as currently configured.
## Chain 1: Reducing each adaptation stage to 15%/75%/10% of
## Chain 1: the given number of warmup iterations:
## Chain 1: init_buffer = 7
## Chain 1: adapt_window = 38
## Chain 1: term_buffer = 5
## Chain 1:
## Chain 1: Iteration: 1 / 100 [ 1%] (Warmup)
## Chain 1: Iteration: 10 / 100 [ 10%] (Warmup)
## Chain 1: Iteration: 20 / 100 [ 20%] (Warmup)
## Chain 1: Iteration: 30 / 100 [ 30%] (Warmup)
## Chain 1: Iteration: 40 / 100 [ 40%] (Warmup)
## Chain 1: Iteration: 50 / 100 [ 50%] (Warmup)
## Chain 1: Iteration: 51 / 100 [ 51%] (Sampling)
## Chain 1: Iteration: 60 / 100 [ 60%] (Sampling)
## Chain 1: Iteration: 70 / 100 [ 70%] (Sampling)
## Chain 1: Iteration: 80 / 100 [ 80%] (Sampling)
## Chain 1: Iteration: 90 / 100 [ 90%] (Sampling)
## Chain 1: Iteration: 100 / 100 [100%] (Sampling)
## Chain 1:
## Chain 1: Elapsed Time: 4.18487 seconds (Warm-up)
## Chain 1: 9.11498 seconds (Sampling)
## Chain 1: 13.2998 seconds (Total)
## Chain 1:Posterior distribution of topic in each sample
theta = samples$theta
names(theta) = c("theta", "Sample", "Topic")
dimnames(theta)[[2]] = sample_names(ps)
dimnames(theta)[[3]] = c(paste0("Topic ", seq(1,K)))
theta.all = melt(theta)
colnames(theta.all) = c("Iteration", "Sample", "Topic", "topic.dis")
theta.all$Sample = factor(theta.all$Sample)
theta.all$Topic = factor(theta.all$Topic)
# add control or dilution series
sam = sample_data(ps) %>% data.frame()
sam$unique_names = rownames(sam)
theta.all = left_join(theta.all, sam, by =c("Sample"= "unique_names"))
theta.all$Sample_Type = factor(theta.all$SampleType)Topic distirbution in each sample
ggplot(data = theta.all) +
geom_boxplot(aes(x = Sample,
y = topic.dis,
color = Topic)) +
facet_grid(Topic ~ Sample_Type, scales = "free_x") +
ylab(bquote(theta[k])) +
ggtitle("") +
theme(plot.title = element_text(hjust = 0.5, size = 15),
strip.text.y= element_text(size = 12),
strip.text.x = element_text(size = 12),
axis.title.y = element_text(size = 12),
legend.position = "none")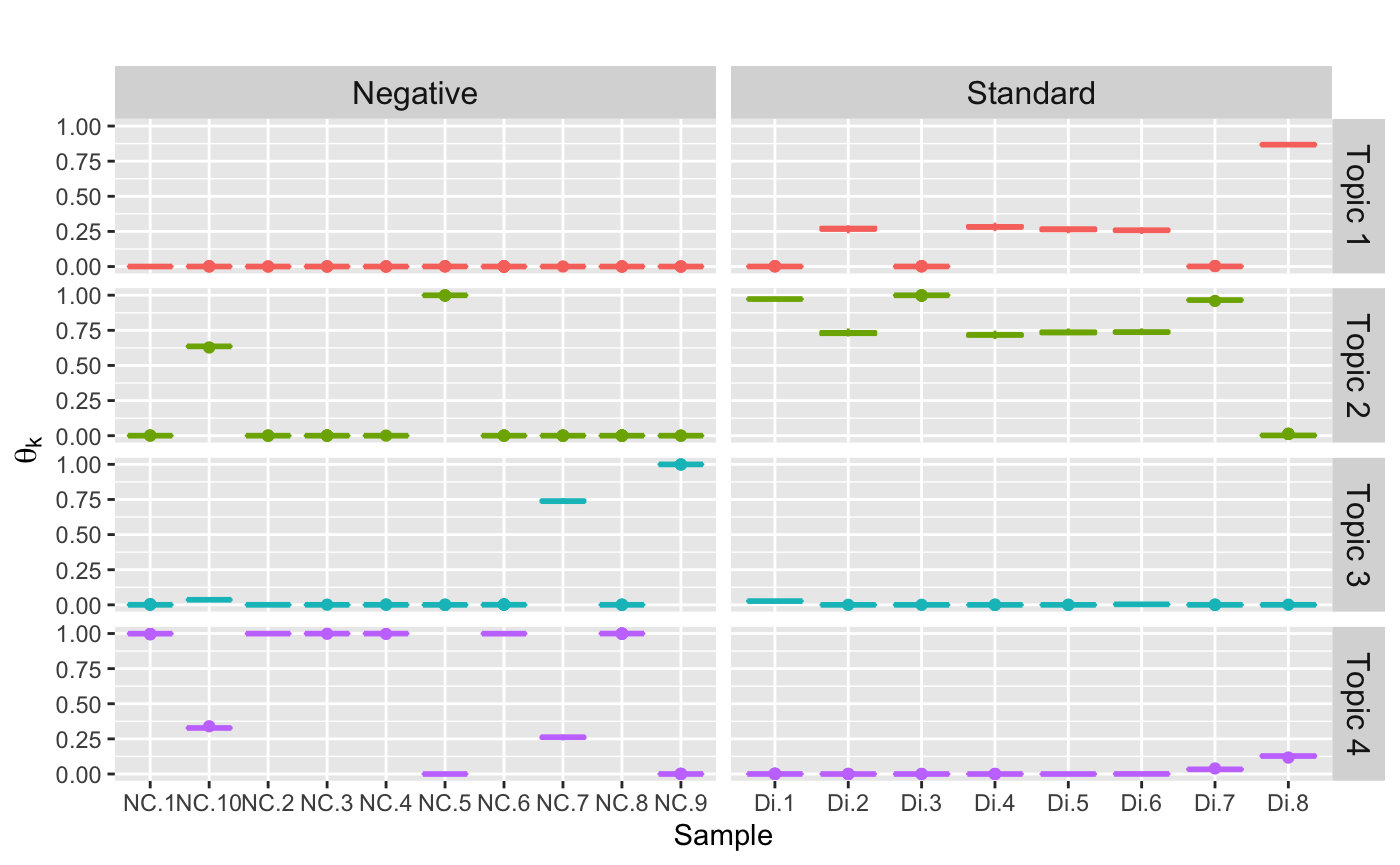
ASV cloud in each topic
beta = samples$beta
dimnames(beta)[[2]] = c(paste0("Topic ", seq(1,K)))
tax_tab = tax_table(ps) %>% data.frame()
tax_tab = mutate(tax_tab, seq.variant = rownames(tax_tab))
dimnames(beta)[[3]] =tax_tab[, "seq.variant"]
beta.all = melt(beta)
colnames(beta.all) = c("Chain", "Topic", "ASV", "ASV.distribution")
beta.all$ASV = as.character(beta.all$ASV)
beta.all = left_join(beta.all, tax_tab, by = c("ASV"= "seq.variant"))
beta.all$Topic = factor(beta.all$Topic)
beta.all$ASV = factor(beta.all$ASV)max.beta.in.each.asv.all.topics = group_by(beta.all,
Topic,
Family,
Genus) %>% summarise(max_beta = max(ASV.distribution)) %>% top_n(10, max_beta) %>% as.data.frame()
ggplot(max.beta.in.each.asv.all.topics,
aes(label = Genus, size = max_beta, color = Family)) +
geom_text_wordcloud() +
theme_minimal() +
scale_size_area(max_size = 8) +
facet_wrap(~ Topic) +
theme(strip.text.x = element_text(size = 12, face = "bold"))
We observed two contaminant topics.
Session Info
## R version 3.6.1 (2019-07-05)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS Mojave 10.14.6
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] parallel stats4 grid stats graphics grDevices utils
## [8] datasets methods base
##
## other attached packages:
## [1] ggwordcloud_0.5.0 reshape2_1.4.3
## [3] DESeq2_1.26.0 SummarizedExperiment_1.16.0
## [5] DelayedArray_0.12.0 BiocParallel_1.20.0
## [7] matrixStats_0.55.0 Biobase_2.46.0
## [9] GenomicRanges_1.38.0 GenomeInfoDb_1.22.0
## [11] IRanges_2.20.1 S4Vectors_0.24.1
## [13] BiocGenerics_0.32.0 ggplot2_3.2.1
## [15] magrittr_1.5 gridExtra_2.3
## [17] gtable_0.3.0 HDInterval_0.2.0
## [19] dplyr_0.8.4 phyloseq_1.30.0
## [21] BARBI_0.1.0 BiocStyle_2.14.0
##
## loaded via a namespace (and not attached):
## [1] backports_1.1.5 Hmisc_4.3-0 plyr_1.8.5
## [4] igraph_1.2.4.2 lazyeval_0.2.2 splines_3.6.1
## [7] usethis_1.5.1 inline_0.3.15 digest_0.6.23
## [10] foreach_1.4.8 htmltools_0.4.0 fansi_0.4.0
## [13] checkmate_2.0.0 memoise_1.1.0 cluster_2.1.0
## [16] remotes_2.1.0 Biostrings_2.54.0 annotate_1.64.0
## [19] pkgdown_1.4.1.9000 prettyunits_1.0.2 colorspace_1.4-1
## [22] blob_1.2.0 xfun_0.11 callr_3.4.0
## [25] crayon_1.3.4 RCurl_1.95-4.12 jsonlite_1.6.1
## [28] genefilter_1.68.0 survival_3.1-8 iterators_1.0.12
## [31] ape_5.3 glue_1.3.1 zlibbioc_1.32.0
## [34] XVector_0.26.0 pkgbuild_1.0.6 Rhdf5lib_1.8.0
## [37] rstan_2.19.3 scales_1.1.0 DBI_1.0.0
## [40] Rcpp_1.0.3 xtable_1.8-4 htmlTable_1.13.2
## [43] foreign_0.8-72 bit_1.1-14 Formula_1.2-3
## [46] StanHeaders_2.21.0-1 htmlwidgets_1.5.1 RColorBrewer_1.1-2
## [49] acepack_1.4.1 ellipsis_0.3.0 farver_2.0.3
## [52] pkgconfig_2.0.3 loo_2.2.0 XML_3.98-1.20
## [55] nnet_7.3-12 locfit_1.5-9.1 labeling_0.3
## [58] tidyselect_1.0.0 rlang_0.4.4 AnnotationDbi_1.48.0
## [61] munsell_0.5.0 tools_3.6.1 cli_2.0.0
## [64] RSQLite_2.1.3 ade4_1.7-13 devtools_2.2.1
## [67] evaluate_0.14 biomformat_1.14.0 stringr_1.4.0
## [70] yaml_2.2.0 processx_3.4.1 knitr_1.26
## [73] bit64_0.9-7 fs_1.3.1 purrr_0.3.3
## [76] nlme_3.1-142 compiler_3.6.1 rstudioapi_0.10
## [79] curl_4.3 png_0.1-7 testthat_2.3.1
## [82] tibble_2.1.3 geneplotter_1.64.0 stringi_1.4.3
## [85] ps_1.3.0 desc_1.2.0 lattice_0.20-38
## [88] Matrix_1.2-18 vegan_2.5-6 permute_0.9-5
## [91] multtest_2.42.0 vctrs_0.2.3 pillar_1.4.3
## [94] lifecycle_0.1.0 BiocManager_1.30.10 data.table_1.12.6
## [97] bitops_1.0-6 R6_2.4.1 latticeExtra_0.6-28
## [100] bookdown_0.16 sessioninfo_1.1.1 codetools_0.2-16
## [103] MASS_7.3-51.4 assertthat_0.2.1 pkgload_1.0.2
## [106] rhdf5_2.30.1 rprojroot_1.3-2 withr_2.1.2
## [109] GenomeInfoDbData_1.2.2 mgcv_1.8-31 rpart_4.1-15
## [112] tidyr_1.0.2 rmarkdown_2.0 base64enc_0.1-3